Hey! Just wanted to let you know about my company: Svix - Webhooks as a Service.
This is the blog version of the talk I gave at Samsung's UK office. People have been asking for a blog version, so here it is. While it covers mostly the same topic as the talk, it's not exactly the same. If you are only going to look at one of them, it's better to read this post.
I'm intentionally brief throughout this post. The goal of this post is to expose you to new commands you may have not known. However, it should only serve as a starting point, and it's up to you to further explore those you found useful.
This post assumes some basic working knowledge of git, though still covers some basics. If you feel like you're already familiar with git, you can skip past the introduction
Quick Setup Before We Begin
In case you don't already have these set, you should set your name and email. I set
the globally to all repos, but if you omit the --global-- directive, you can set them locally per repo.
$ git config --global user.name "Tom Hacohen"
$ git config --global user.email "tom.git@stosb.com"
You should also enable colours, set your default editor (what git will use for
editing commit messages, for example) and an external tool that can be used to view diffs
when running git difftool
$ git config --global color.ui true # Default since git 1.8.4
$ export EDITOR="vim" # Optional
$ git config --global diff.tool "vimdiff" # Extra optional
You should also enable git command autocompletion (system dependant).
At this point it's also worth mentioning that git has built-in support for aliases. Some of the commands presented here will be rather long, so it may be useful to alias some of the more commonly used ones.
$ git config --global alias.unstage 'reset HEAD --' # Set it up
$ git unstage # Use it
A Few Useful Properties of Git
Branches and Tags are References
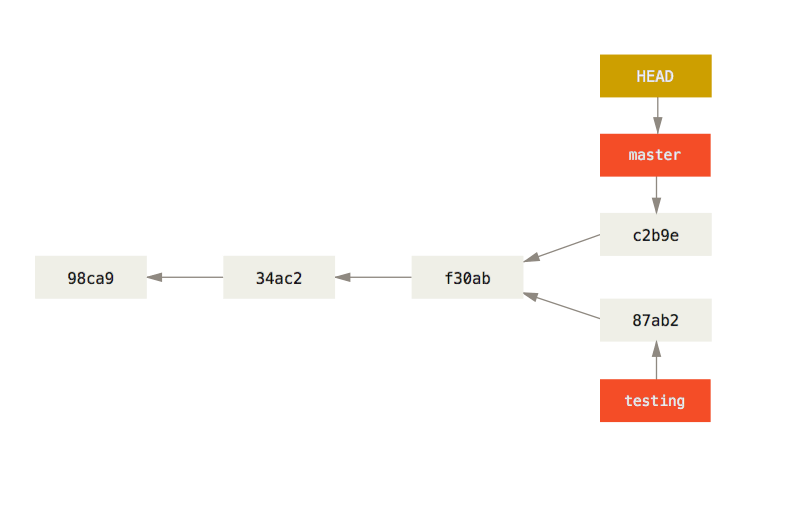
Branches and tags are just references to commits, and master is just a normal branch, so a reference too. This means you can make branches and tags point to any commit in your history, or use them like you would any commit hash.
Nearly Every Operation is Local
Because of git's decentralised nature, all the operations other than the ones that sync with a remote (either push or pull/fetch) are local. This means that:
- Operations are usually very fast
- You can wore offline, while for example on a plane
- You can be sloppy and clean up after yourself before pushing your changes.
A Few More Useful Properties…
- Has a staging area, so you can add only some of your changes and commit when ready.
- You can rewrite history by rearranging and amending commits.
- History is immutable, so all of your commits are recoverable, even if you rewrote history (unless you ran garbage collection).
- Everything is referenced by its cryptographic hash, so you can be certain your commit history or files have not bee corrupted or maliciously modified.
Referencing Commits
As mentioned above, branches, tags and commit hashes can be used interchangeably. There is also a special pointer called HEAD that always points to the current commit/state we are on.
In addition, git supports a few modifiers that make referencing your commits very easy.
$ git show 7c1c793fe8769980823bfbfcf80396486c6163d7 # Full commit hash
$ git show 7c1c793fe87 # Shorter hash
$ git show 7c1c793 # Even shorter hash (can be any length as long as not ambiguous)
$ git show HEAD # Current head
$ git show master # The commit master points to
$ git show some_tag # The commit some_tag points to
## Reminder: all reference types can be used interchangeably
$ git show HEAD^ # HEAD's parent
$ git show master^^ # master's grandparent
$ git show some_tag~3 # some_tags's great-grandparent
$ git show 7c1c793~4 # This commit's great-great-grandparent
$ git show master@{yesterday} # The commit master pointed to yesterday
Reading the Log
Cleaner Tree Log Overview
$ git log --oneline --graph * 7b3fa8a Migrate elementary to the new Eo4 syntax |\ | * 02e87e8 Fix warnings following migration to Eo4. | * 7bd1d48 Map: Correct broken migration. | * e74ec8c Automatic migration to Eo4. | * 9274efb Remove redundant defines. |/ * 36669f1 Scaling test: reorder instructions to set the correct scale * b9c912f radio: inherit from elm check
Listing a Change Summary
$ git log --stat commit a31f399857ecf9409e6aa6fb8effe9477ee47fe2 Author: Tom Hacohen <tom@stosb.com> Date: Wed Jun 22 16:52:05 2016 +0100 Edje object: Add API for replacing the internal text object src/lib/edje/edje_load.c | 34 ++++++-------------------- src/lib/edje/edje_object.eo | 17 ++++++++++++++ src/lib/edje/edje_private.h | 1 + src/lib/edje/edje_util.c | 32 +++++++++++++++++++++++++++ 4 files changed, 60 insertions(+), 24 deletions(-)
Seeing Actual Code Changes
$ git log -p commit c66d478ebb2c1a0aff52571467d7a6b87a533382 Author: Ji-Youn Park <jy0703.park@samsung.com> Date: Thu Mar 24 17:54:05 2016 +0830 Elm_image: remove Elm_Image_Orient. diff --git a/src/lib/elm_image.c b/src/lib/elm_image.c ********** Snip Snip ********* } EOLIAN static void -_elm_image_orient_set(Eo *obj, Elm_Image_Data *sd, Elm_Image_Orient orient) +_elm_image_efl_image_orientation_set(Eo *obj, Elm_Image_Data *sd, Efl_Gfx_Orientation orient) { if (sd->edje) return;
Limiting Commits
## Commits changing file/function in file
$ git log main.c
$ git log -L :list_find:main.c
## Commits containing string
$ git log --grep FOOBAR # Messages containing string
$ git log -S FOOBAR # Lines containing string
## Commits in HEAD, not in master
$ git log master..
## Commits that are in either "foo" or "bar" (not both)
$ git log foo...bar
## Only show the first parent (don't show commits in merged branches)
$ git log --first-parent
Finding Out What You Have Been Up To
## The total number of commits by an author
$ git shortlog -nse --author=tom.git@stosb.com
## The total number of commits by an author in the last year
$ git shortlog -nse --author=tom --since="1 year ago"
## A list of commits by an author in the last year
$ git log --author=tom --since="1 year ago"
Getting a Version Description
While git's hashes are useful for pointing to specific commits, they are not very convenient as version identifiers as it's not possible to know which commit is newer just by looking at it.
There are two ways to go around this. The first is using git decsribe, a built in git command that prints out a usable description for a commit. For example, the commit below was 236 commits after the tag v1.17.0 and its short hash was gc66d478. Or alternatively, it was 12514 commits since the origin of the repo.
## Get a standard version description (requires at least one tag)
$ git describe --long
v1.17.0-236-gc66d478
## Get the SVN-like monotonic revision number
$ git rev-list --count HEAD
12514
Inspecting Commits and State
## Showing the changes in a commit
$ git show 80f14e8fea0057ee950f0778dd51b096ca9850a4
$ git show my_branch # Can be branch, tag or whatever.
## Showing a file from a different state
$ git show v1.7.0:main.c
## Switching working directory to a different reference
$ git checkout c9b306777 # Or any other reference
Branches
Viewing
## All the branches (including remote)
$ git branch -a
## Use "git fetch -p" to clean up stale remote branches
## All branches that are fully contained in HEAD
$ git branch -a --merged
## All branches that are not full contained in HEAD
$ git branch -a --no-merged
Manipulating
I think it's very important to maintain a linear history. Most of the commands here help you maintain that.
Rebase reorders your current branch over another, and git merge --no-ff makes sure that merges always create a merge commit, even if not necessary (which it never is when you have linear history). This helps you group changes together like you would with any other merge.
Last, but not least is the --preserve flag which makes sure the aforementioned redundant merge commits are not discarded when rebasing.
## Rebase branch over the upstream version
$ git pull --rebase # Can be set in config
## Rebase branch over a specific branch
$ git rebase origin/master
## Merge a branch and always create a merge commit
$ git merge --no-ff
## Rebase and keep the branch structure
$ git pull --rebase=preserve
$ git rebase --preserve-merges origin/master
## Applying a commit from a different branch
$ git cherry-pick 80f122437d
Making Changes
Inspecting Workspace State
## A more condensed status
$ git status -s
## Changes compare to upsteram
$ git diff origin/master
## Seeing the diff of the staging area
$ git diff --cached
## Ignore whitespace changes in diff
$ git diff -w
Adding Files to the Staging Area
## Adding parts of a file
$ git add -p file # File can also be a dir, or ommitted
## Adding all of the changed files in a directory
## Very useful when resolving conflicts
$ git add -u src/
Using the Stash
## Stashing all of the changes
$ git stash
## Stashing some of the changes
$ git stash -p
## Applying back the stash
$ git stash apply
## Stash has many more features I do not use
$ git stash --help
Rewriting History
It is a very bad idea to rewrite published history. That is, history that has been shared with the world (by for example, git push) to a shared branch. It's OK to change the history of a temporary feature branch, and is for example how you update a PR on GitHub and GitLab.
This section is therefore here to help you rewriting your local history before you publish, so the published commit history is clean and easy to follow.
Un-staging Files
$ git status -s M README $ git reset README # git reset # for all the files $ git status -s M README $ git checkout README # Use "git checkout -f" for all of the files $ git status -s # Nothing
Editing the Most Recent Commits
## Remove the most recent commits and their changes
$ git reset --hard HEAD^
$ git reset --hard HEAD~3 # Or any other pointer (for a range)
$ git reset --hard origin/master # Reset the state to upsteam
## Keep the changes uncommitted
$ git reset HEAD^
$ git reset c9b306777 # Or any other pointer
## Unstage changes
$ get reset
## Merging index into the most recent commit
$ git add NEWS
$ git commit --amend # Also lets you edit the commit message
## Add -v to git commit to also see the diff
## Edit the author
$ git commit --author "007 <jb@mi6.gov.uk>" --amend
The Most Useful Command in The World
This is hands down the most useful command. I use it a lot! This command lets you edit all of the commits in a certain range, and I use it to rearrange and clean up my commits.
# Will open in your default editor set in EDITOR $ git rebase -i HEAD~5 pick 7b07b03 track/manage size hints for zoomap child objects pick 71a85b7 update winlist ui when using directional selection pick bbd4d2f force changed when adding keyboards pick a424542 disable emotion_shutdown during shutdown procedure # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # d, drop = remove commit # # These lines can be re-ordered; executed from top to bottom. # If you remove a line here THAT COMMIT WILL BE LOST.
Recovering Lost Commits
The problem with changing history is that history can be lost. It's very common to want to revert to a previous state or recover an accidentally lost or modified commit.
Since git's history is immutable, commits are never lost (unless garbage collected and can still be referenced by their hash, or if the hash is unknown, can be found using the method below.
# Jump to a hash state if you know it $ git checkout c9b306777 # Find unreferenced (missing) commits $ git reflog cebf78d HEAD@{0}: rebase -i (finish): returning to refs/heads/master cebf78d HEAD@{1}: rebase -i (start): checkout HEAD^^^^ c6e355f HEAD@{2}: rebase finished: returning to refs/heads/master c6e355f HEAD@{3}: pull --rebase: Elementary test entry: Create an editable test object. 83b0592 HEAD@{4}: commit: Elementary test entry: Create an editable test object. 2fd8861 HEAD@{5}: commit (amend): Ui text: Add an editable variant (tiny wrapper).
Afterwards you can just cherry-pick, reset, checkout or whatever method to recover those commits.
Removing Parts of a Commit
It's also very common to accidentally commit a file or a line that you didn't intend to. Especially when using git commit -a. This too can be easily fixed.
## Commit c42bc3a535 (can be anywhere in history)
$ git revert -n c42bc3a535
$ git reset # Remove everything from staging
## Add back the wanted changes
$ git add NEWS # All of this file
$ git add -p # Some parts of the rest
## Merge the commit into the original commit
## Either amend if it is the HEAD
$ git commit --amend
$ git checkout -f # Remove the rest of the changes
## Or fixup if anywhere else
$ git commit -m "Temp"
$ git checkout -f # Remove the rest of the changes
$ git rebase -i c42bc3a535^ # Mind the ^ (caret)
Delivering Changes
## Change the url of the repository
$ git remote set-url origin ssh://git@newserver.com/repo.git
## Adding a new remote
$ git remote add new ssh://git@alt.newserver.com/repo.git
## Using the new remote
$ git fetch new
$ git rebase new/master
$ git push new master
## Generate patch files for a series of commits
$ git format-patch HEAD~5 # Or any other reference
Investigating Bugs
Finding Who Added a Line and Why
## Check who changed the file
$ git blame eo.c # Add "-w" to ignore white-space
06f65ab2 eo.c (Tom Hacohen 2016-05-19 11:33:17 +0100
321) vtable = &klass->vtable;
fc880379 eo.c (Tom Hacohen 2015-11-09 11:45:04 +0000
322) inputklass = main_klass = klass;
7be0748b eo.c (Jérémy Zurcher 2013-07-30 15:02:35 +0200
323)
c2b4137f eo.c (Carsten Haitzler 2015-10-24 12:23:53 +0900
324) if (!cache->op)
## At an earlier revision
$ git blame fc880379^ -- eo.c
Finding When a Bug Was Introduced
This command helps you run a binary search on the commit history efficiently finding a bad commit.
All you need to do is run bisect, evaluate a commit to see if it was broken or not, and then report the result to git. You can even skip commits by passing skip instead of good or bad.
$ git bisect start
## To limit bisect to a directory: "git bisect start -- src/"
## Set the initial known good and bad commits
$ git bisect bad COMMIT
$ git bisect good COMMIT
Bisecting: 417 revisions left to test after this (roughly 9 steps)
[7352bcff98fc65a08edcd505b872403af8d821a7] edje_external: fix external icon handling
$ git bisect good # Or bad if bad
Bisecting: 208 revisions left to test after this (roughly 8 steps)
[9f5d27972252d67fe92ca44a1c610da4ed531b86] Evas events: Implement support for hold event
## ... SNIP ...
a31f399857ecf9409e6aa6fb8effe9477ee47fe2 is the first bad commit
Automatic Bisect
While git bisect saves you a lot of time and effort, it still involves manually testing commits and reporting the results back to git. You can alternatively write a script that will automatically evaluate commits for you.
For example consider this script:
#!/bin/sh
make || exit 125 # this skips broken builds
~/check_issue.sh # does the test case pass?
It compiles the code, and runs ~/check_issue.sh, our small test program that returns 0 on success, and anything else on failure. Then all you need to do is run:
$ git bisect start HEAD HEAD~10 -- # Last 10 commits, short-hand form for start
$ git bisect run ~/test.sh
$ git bisect reset # quit the bisect session
a31f399857ecf9409e6aa6fb8effe9477ee47fe2 is the first bad commit
Releasing Versions
We have now finally fixed all the bugs, merged all the feature branches, cleaned up the change history, and pushed our changes to our remote repository. There is only one thing left, tagging the release.
## Bare tag, just hold a reference to a commit: not recommended.
$ git tag v1.0.0 # You can also pass an optional commit reference
## Annotated tag, also add a message to the commit, for example, a changelog: recommended
$ git tag -a v1.0.0 # Again, you can also pass an optional commit reference
## Cryptographically igned tags: assuring your users this tag really came from you: recommended
$ git tag -s v1.0.0 # Again, you can also pass an optional commit reference
A Few More Commands Worth Checking Out
git submodulegit send-emailgit checkout -b- Use git with other VCS:
git-svn,git-hgand more - CLI viewer:
tig - GUI viewers:
gitgandgitk
Finishing Notes
Git is a powerful tool, and this post only scratches the tip of the iceberg. I highly recommend you take the time to read the wonderful git book. It's not a very long read, and is well worth it.
Please let me know if you spotted any mistakes or have any suggestions, and follow me on Twitter or RSS for updates.